Processing RSS feeds
Introduction
This tutorial gives an overview on how to load RSS feeds into Processing.org sketches, how to read and use the available data, and how to display these.
Read this general introduction or jump directly to the tutorial kick off or to the first examples with explanations.
RSS
RSS (Real Simple syndication) is a format for delivering regularly changing web content.
An RSS file consists of both static information about the feed, as well as dynamic items. These items normally are news items or blog entries, but they can be about any web-accessible content.
Each item is inside an <item> element and contains among others a title, a url, and a description.
Depending on the specific feed, other elements can appear. They can contain further metadata, or link to media files, such as images, and flash movies, but any data could be described in RSS (feed readers simply ignore elements which they don't recognize).
- What Is RSS? - RSS Primer: One Page Quick Introduction to RSS
XML
RSS formatted files are specified using XML (as are many other web formats, such as HTML, or SVG). XML (Extensible Markup Language) is a markup language for documents containing structured information. These are structured as elements, attributes, values, and others. For instance, in
the guid is the element, the isPermaLink is an attribute (with an attribute value of true), while http://btk.tillnagel.com/2007/01/01 is the content value.
The elements can be structured hierarchically. If you look in the above RSS example you see that <item> has three sub-elements (title, link, description). These are called children elements.
To read and write XML files in Processing there are different possibilites. Besides Processing XML libraries such as proXML, there are also full-blown frameworks such as dom4j. But for now, we stick to the Processing core library.
- XML Libarary - processing.org
(For further information on how to read RSS feeds with more complex libraries visit this Code & form article "Read RSS feeds in Processing")
Finding data
There are myriads of RSS feeds in the wild wild web. Besides your favourite blog, there are a lots of web feeds with a huge range of diverse non-news data. For instance, weather forecasts, last uploaded photographs, or personal link recommendations.
The general path to find good data is to
- Choose an RSS feed
- Analyze the XML structure
- Identify interesting data
- Select XML elements and values
- Do creative stuff
Load and use feeds in Processing
So, let's say you have chosen the RSS feed about Processing updates (http://processing.org/updates.xml). Now load that feed and start utilizing the information therein.
Analyze feed
First, take a look which information the chosen feed has. Therfore, open the feed URL in your browser, and view the page source. Then you can see the XML structure and decide which data to use, and how to access it.

RSS feed shown in Firefox (clipping)
Using XML in Processing
To load an RSS feed (or any other XML file) create a new XMLElement and provide a URL in the constructor.
Afterwards, walk through the XML structure to the elements to use. To begin, simply get the title of each item with rss.getChildren("channel/item/title").
The paramater specifies which elements to return as array. The XPath channel/item/title selects the elements hierarchically
– compare to the XML structure above.
Inside the loop get the content of every title element, and store it for later use.
Besides getContent() the other important method is getStringAttribute(attrName) to get the value of an attribute of the element.
- XMLElement - Processing Reference
- XMLElement.getChildren() - Processing Reference
- XMLElement.getStringAttribute() - Processing Reference
Example: SimpleFeedReader
Loads RSS feed and stores the titles of each item in an array.
- SimpleFeedReader.pde (source), SimpleFeedReader.zip (complete sketch archive)
Example: SimpleFeedVisualizer
Loads RSS feed and visualizes the titles in a very simple manner. Color and bar depend on the length of the corresponding title.

- SimpleFeedVisualizer.pde (source), SimpleFeedVisualizer.zip (complete sketch archive)
- String - Processing Reference
- Creative Coding: Texte & Typographie - course lecture in German
Use media files
Besides reading text data like title, or description you can also get media files from a feed. Given that the feed contains these data.
BBC News for instance provides a thumbnail image for each of their news items.
First, all <media:thumbnail> elements are extracted from the RSS file (line 7) with the getChildren() method.
Then, in line 9 the URL of the image is read (from an attribute). Next, the image is loaded from that web address and stored in an PImage variable (line 10). As you can see the loadImage() function
not only is able to load image files from the data folder but also directly from an internet address.
- XMLElement.getStringAttribute() - Processing Reference
- loadImage() - Processing Reference
- Media RSS Module - See the examples at the bottom of the page for other media types.
Keep in mind that the way how to access media files (or any other element) can differ from feed to feed. Always look in the specific RSS XML structure first (see Analyze Feed paragraph).
Example: FeedVisRadialThumbnails
Displays the image thumbnail of each item in a radial layout. The user can rotate and scale the image wheel with the mouse, interactively.
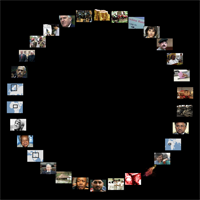

- FeedVisRadialThumbnails.pde (source), FeedVisRadialThumbnails.zip (complete sketch archive)
Example: FeedVisColoredTitles
Displays titles in a color picked from the center of the thumbnail. Images and headlines scroll over the screen.

- FeedVisColoredTitles.pde (source), FeedVisColoredTitles.zip (complete sketch archive)
Item class
To simplify using the item information, and to ease storing, updating, and displaying each item's data the following class can be used as a basis:
This class (or an extended version of it) is used in the two examples above.
- Item.pde (source), ColoredScrollingItem.pde (extended source)
- Creative Coding: Objektorientierte Programmierung, OOP 2, OOP 3 - course lectures in German
Download data from within an applet
"For security reasons, a Processing sketch found online can only download files from the same server from which it came." (from Processing Reference - loadImage())
Thus, all examples from this tutorial do not work correctly if run on the web. Whether loading RSS feeds, or external images, the processing sketch is permitted to do this only if run offline.
So to get RSS feeds from another server you need a special page on your server, which forwards the original data.
(Explanations need to be written.) For now, visit this thread at the Processing discussion board:
Topic with how-to create a PHP file